Handling data in (alternative) social networks
Roses are red, Facebook is blue. Alternative social networks are what we want, but on implementing them… we have no clue.
Fancy poems aside, it feels like more and more people these days think, and discuss, about alternate social networks. Driven by privacy concerns after recent events on the large legacy1 platforms or by general curiosity, most of these discussions seem to be focused on how alternative social networks handle data and try to ensure privacy for their users. However, there is more to this than just privacy: picking a core architecture also has a considerable impact on comfort, maintainability, cost, scalability, reliability, and resilience against censorship.
I started working on a federated social network almost 8 years ago, so one could say I have a bit of experience in that field; based on that, I have opinions. Even though I clearly favor a federated approach as indicated by the number of resources I spent on such projects, I do not think they are the ultimate goal we all should be heading towards but that the ultimate goal has not been invented yet.
To allow this post to be shared within less technical circles, I will try to explain each concept with a non-technical model by comparing these architectures with common interactions: You are Charlie, and you want to send postcards (social media posts) to your friends Alice and Bob, and a letter (private message) to Alice.2
For lack of better formatting options, I will put those paragraphs into a blockquote, like this one.
Centralized systems
You drive to a large building in the town’s center. There, you hand over your letter and postcards to the reception desk and leave. People inside that building will store your items, and when Alice and Bob come along and ask for their new stuff, the reception will hand out your postcard and letter to Alice, and Bob will receive a postcard.
If the people inside the building do their job as they should, that is. You have no way of observing their work, and they may read, alter, or destroy your postcards and letters if they feel like it, and they may change the presentation or order in which they hand out the items to Alice and Bob.
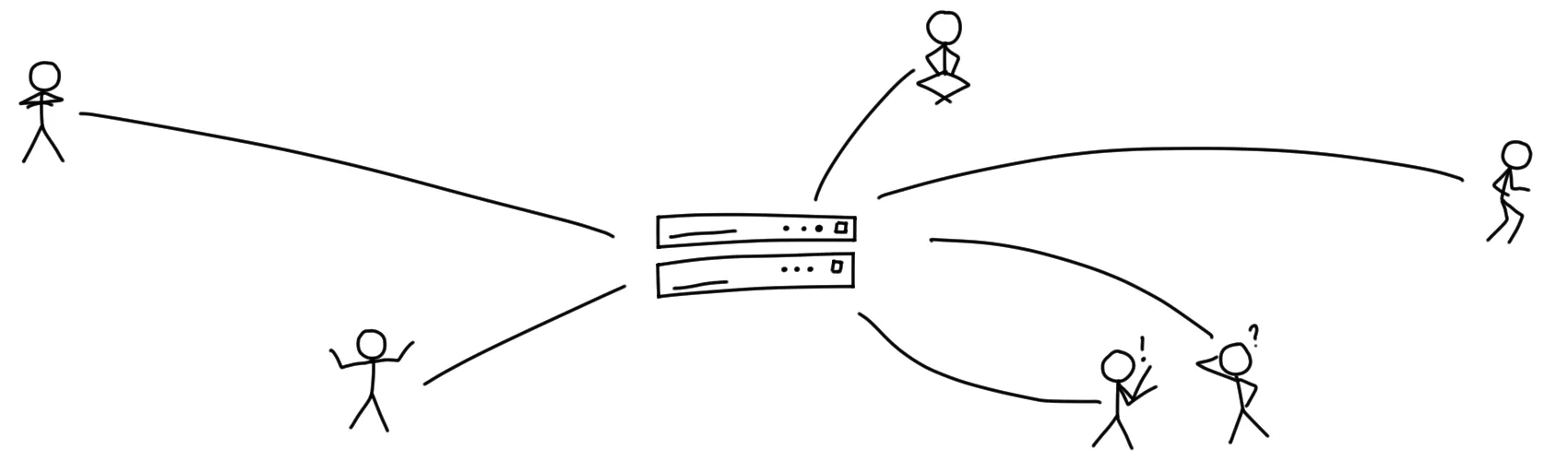
This, basically, is how the large networks (read: Twitter, Facebook, and the others) work right now. All data is stored by and at some central entity, and that entity has total control over all incoming and outgoing data. This has some pretty obvious downsides, but there are some good aspects as well.
Let’s look at the advantages of central infrastructure first. When one central party has control over all the data, there are a lot of cool things they can do with that. It is much simpler to scale a system if you know exactly where each piece of data is coming from and where it is stored, and although it is expensive and not trivial to build such systems, it can be done if you have enough money and engineering power.
Another very important aspect when considering the needs of social media users is the discovery of both contacts and contents. One of the main reasons people use social networks is to stay in touch with old friends and family members, and it is crucial that finding these people and their posts is as comfortable as possible. When all data is collected in one central hub, the system can efficiently use big data magic to make contact suggestions, sync address books, correlate geo-location data, and use other means of data analysis to make finding stuff easy and comfortable.
Now, for the bad parts. The fact that all private information is collected at one large entity not only opens the door for data analysis that increases comfort and usefulness, but the data can also be analyzed for… less beneficial usages. When you collect a lot of private information, building precise profiles of one’s behaviors and personality traits is easy, and the advertising industry and other companies are generally very interested in such data. Building and maintaining large central networks is expensive, so turning user’s data into profit is one common way of keeping a service free as in free beer for users.
Everyone on the centralized network has to obey the rules of said central entity. Depending on the kind of network and the kind of entity running it, this may not be a bad thing, but it opens the door for trouble around unclear policies, content removals, account locks, and all the other events we see on the internet every day. Also, as all the data has to flow over some central points, centralized models make it relatively easy for governmental entities to observe, or control, the flow of information, and with enough pressure, the central network may be forced to hand over or adjust data following governmental decisions.
Data safety and reliability may be a concern in central networks as well. Although the large systems are generally well distributed and do their best to keep service availability as high as possible, there is little the users can do if the service is down for whatever reason, be it a temporary service disruption or the company behind the product merely going out of business. If the central party is gone, all the traffic stops flowing, and all the data is gone with it.
Peer-to-peer data exchange
You take your bicycle, drive to Alice’s house, find her inside, and hand over the postcard and the letter. After that, you drive to Bob’s house, and you deliver him a copy of the postcard as well.
Unfortunately, the next day when you want to deliver a letter to Bob, he appears to not be at home, so you cannot hand the message over and have to try again at a later time.
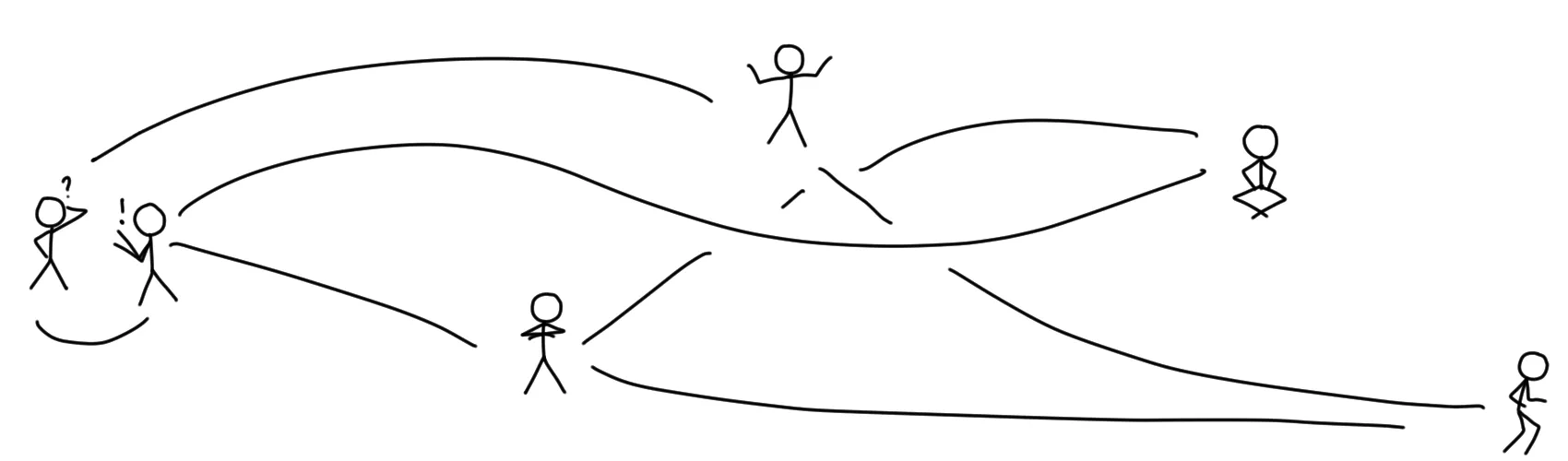
In classical Peer-to-Peer networks (P2P for short), there are no servers, and clients talk directly to each other. This is pretty much the opposite of centralized networks. Instead of delivering all your data to a central hub and trusting them to forward it to or share it with the right people, you take over the role of being the delivery person and take care of that yourself.
Recently, there has been an increase in research on P2P systems with projects such as libdweb, but finding an example for a P2P social networking project is actually not that easy, as most of them depend on some kind of semi-central infrastructure. However, there are some projects such as Pandora that work without any central dependency, and that comes with its own pros and cons.
The lack of any central infrastructure avoids some of the pitfalls of centralized networks that were outlined earlier. If your communication does not depend on anyone but you and the recipient, there is no entity that could somehow read, influence, or block the contents that get distributed, and as long as you find a way to somehow connect to your peer, you will be able to exchange anything you want3.
In my opinion, there is a lot of space for P2P applications, and I am looking forward to what the future comes up with. I am especially curious about new means of file transfer, as we still did not really solve this issue. Some of the work on making web content less prone to server failures by distributing the website contents on a large number of clients is also super fascinating. But unfortunately, the way social media is used by the mainstream crowd violates some of the requirements for working true P2P networks that do not depend on some semi-centralized entities.
You see, when we want to design an alternative social network that gets accepted and adopted by large numbers of non-techies, we have to look at how these people use social networks, and design our software around that. We will not get anywhere if we keep looking at ourselves and our usage patterns, as the software will probably be rather unattractive to non-technical folks if we do that.
The reality is that today, most interactions on social media happens on mobile devices, and this is actually somewhat unsurprising if you see social networks as a place for sharing life events and staying in touch with friends. Peer-to-peer networks are designed to have clients directly talking to each other, and for mobile users, that would require smartphones being able to establish a direct connection between each other. While for most computers on a conventional home internet connection this might be just fine, things look different for smartphones and mobile networks. The technical reasoning is somewhat complicated and way beyond the scope of this post4, but it is safe to assume that traditional P2P networks do not work on mobile networks. One side effect of a design that requires peers to communicate with each other directly is the simple fact that to exchange data, both peers have to be “connected” at some point in time. Mobile networks, being as unreliable as they are, may not be a proper transport channel for such a system.
Even if we find solutions that make P2P networks on mobile devices possible, reliable, and efficient, there are more issues to solve here. Although the primary use of social media is on mobile devices, most people regularly switch between devices. They might use their phone during the day but a tablet or a full-size computer in the evenings to read longer articles or watch some of the video contents. When you implement a P2P network the way it is meant to be implemented, all data will be stored on the client that received it. So when people receive posts and comments on their smartphone, the content will not be available on their tablet. One could solve this problem by finding a way to synchronize all devices, but that would increase the application’s complexity a lot.
Additionally, some of the comfortable features that users expect from social networks, such as the easy discovery of new contacts and contents, actually require some kind of central node. In a true peer-to-peer network, it is impossible to “observe” all activity, and a user will only ever see contents that got delivered explicitly to them. This could have been just fine some decades ago when people were okay with exchanging phone numbers and email addresses, but I highly doubt that a system that requires a manual exchange of account identifiers will get much traction today.
Federated networks
Federated social networks are a bit harder to explain, as they are a combination of the two previous approaches. I will try my best.
Instead of delivering your letters and postcards to the large central hub mentioned earlier, you and your neighbors in the same building decide to build a smaller letter-distribution building in front of your house, so that is where you hand over your mail for Alice and Bob. As you built this distribution building together with your neighbors, you can reasonably trust that it will do its job well, because you know who runs it, because you have a direct communication channel to these people, because you are one of them.
The building then looks at the recipient addresses of those letters and sends out its own delivery drivers. Because the address you wrote on the envelope includes a building name, the delivery drivers will drop the letters off at the buildings Alice and Bob built, similarly to yours, and Alice and Bob will be able to pick up their mail from there.
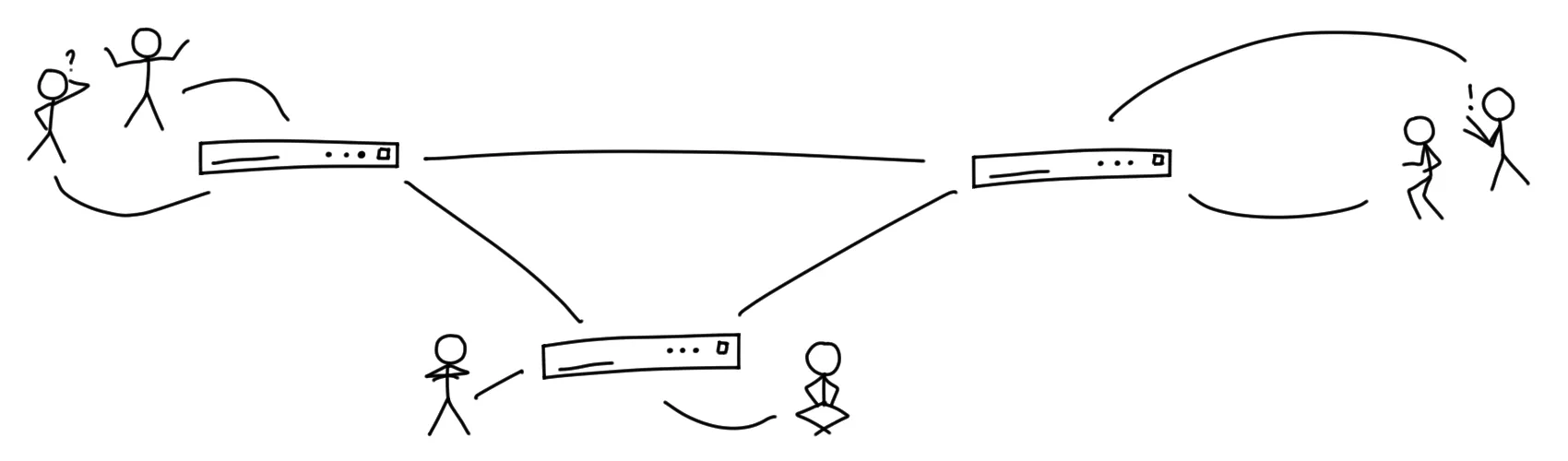
So, you see, there are some kind of central and some kind of P2P elements here, and that is for a reason. This design also has some pro’s and con’s, but before you continue reading this article, I suggest you to read “Federation is the Worst of all Worlds” by Sarah Jamie Lewis first if you have not already. While I do not agree with the title or the conclusion, she raises some valid points there.
Within federated social networks, there are a lot of servers talking to each other, a bit like clients exchanging information in P2P networks. However, because servers are talking to each other and not end-user clients, some of the issues with P2P networks can be avoided. Servers are generally always connected to the internet, have a reliable connection, and do not change locations or IP addresses, so the servers are relatively reliable targets to deliver content to. End-user clients like smartphones can then fetch the data from their servers.
In a perfect world, we would have a lot of servers with small user counts. Like in my example, every user of a server should have a personal connection to the administrator or be the administrator themself, because that is the only way the user can establish a meaningful trust relationship with that server. In reality, though, the story looks different. The amount of servers, compared to the total number of users, is rather small, and this is the case even though most of the users within networks like diaspora* have some kind of technical background at the moment. If we scale our model to audiences like the massive networks have, we would have an even bigger number of non-technical users within the network, and for them, hosting their own node is simply not an option. Also, chances are high that in their direct contact circles, nobody is able to do so, either.
There is an opportunity for non-profit organizations with technical backgrounds and other similar groupings to run such nodes. They could gather the technical (and legal) knowledge required to run a semi-large node but still be local enough to be trustworthy to individual users. But unfortunately, there is no sugarcoating here: for users, in terms of having to trust someone blindly, not much has changed. One could argue that it might be easier to trust a local non-profit instead of? a large, American company, but is there an actual gain? Who knows.
However, I do not think that federated social networks are “the worst of all worlds.” While there is no massive gain in data security for most users, federated networks enable individuals to host their own node and participate in the larger network if they decide to do that. No matter how few nodes there are or how large they become, there will always be more than one node, so the network is more resilient to servers disappearing into the abyss. Even if one server shuts down, not all users of the network will be gone.
Even for data security, federated social networks carry some benefits. When distributing private posts or private messages, distributed systems usually make sure that only nodes that need to know about the item will receive it. So if Alice, Bob, and Carol are all using different nodes, then Alice sends a private message to Bob, and then Carol’s node gets hacked, the stolen data will not include the private message exchanged between Alice and Bob.
So at the end of the day, while I agree that federated systems are not perfect as they currently are, I do not think they are bad, either.
”Zero-knowledge”
In cryptography, the Zero-knowledge proof describes a method of proving knowledge of a value to another party without revealing the actual values in any way. Some web services describe themselves as “zero-knowledge” services, which usually means they store end-user data in encrypted form so that the data is accessible by users but not readable by anyone but the parties with the right keys. Using the term “zero knowledge” in this way has been established by different people so I will use it a bit more loosely as well, but please do not confuse that with actual zero-knowledge proofs.
Zero knowledge systems are, when using a wider definition of the term, already reasonably common. Granted, most of the services are not actually based on zero knowledge, as usually, there is a need to read some metadata, but a lot of services make sure that the actual message contents are kept secret. Everything using end-to-end encryption, where a client application encrypts a message in a way that only the receiving client can decrypt it, can be described as “zero-knowledge” to a certain degree.
For example, if you send PGP encrypted emails, your mail server is aware that you want to send a message to Alice, but without the decryption key owned by Alice, the server cannot read the actual contents. The same goes, for example, for messages sent via Signal. Signal’s servers know that Alice and Bob are exchanging words, but there is no way for the servers to know what Alice and Bob are talking about. The same goes for attackers capturing network traffic or getting access to the servers: they will not be able to read the messages5.
Peer-to-peer networks generally use some form of end-to-end encryption already, so the only theoretical attack vector is the client itself. However, in most federated and centralized systems, data is generally stored in plain text on the servers and only encrypted when exchanged between nodes, or when transferred to a client.
Some people argue that federated networks could be zero-knowledge as well and exclusively handle encrypted objects that can only be decrypted by the clients. Technically, this is true, and implementing such a system would not be that hard. However, this technology would, once again, collide with the way most people use social media and with how most people expect social media to behave.
One of the challenges here is the handling of the actual decryption key. As outlined earlier, users need to be able to use multiple devices to access their contents, and this is where things gets messy. One possible solution is to store the decryption key on the server, protected by a passphrase that is the user’s login password. That way, the client could request the key from the server and unlock it with the passphrase the user uses to log in, but there are some significant issues here. For one, when using a web browser, there is little guarantee that the server, or anyone in between the client and the server, is not going to store the password in any way, which would render the whole cryptography useless. Also, if the user were ever to forget the password, they would be doomed, as there would be no way of regaining access to that decryption key6. The second option would be to use an actual key file, stored exclusively on the clients. However, this would be a significant convenience issue, as the users would have to transfer said key between the clients somehow. If the key is stored on only one device, let’s say their smartphone, and the device gets lost or stolen, they are doomed once again.
There are some more or less complicated solutions to the questions of key security and key exchange between the devices, and these problems ultimately, probably could all be solved somehow. However, there are other problems left unaddressed.
Earlier, we discussed that some of the key features users expect from social media, for instance contact and content discovery, require some server-side knowledge of said contents. A server is unable to suggest you new connections or posts based on tags or other data if the server is unable to look at the actual posts. And even if features like this could somehow be left aside, there are a lot of different points that make social networks feel good. Simple features like meaningful push notifications, for example. I really want to be notified if someone sends me a message or if someone mentions me in a comment, but if I receive a push notification telling me that some stranger whom I only follow for cute cat pictures just posted a photo of their lunch, I might be annoyed. The server needs to know the content to make such decisions. Merely deferring such tasks to the clients will not end well, especially if we are designing a system that will see a lot of mobile usage. We simply cannot send a push notification to the client every time we receive an item and have the client decide if it is worthy of a notification or not, such approaches would create lots of network traffic, and eat a lot of battery.
End-to-end encryption is great and absolutely necessary for some applications. For instant messaging, it is safe to assume that all messages are important and delivering everything directly to the client is usually fine. I do not think the same applies to social networks. And that is only one of the issues that come to mind here.
So… what now?
Now that I have somehow bad-mouthed all of the approaches above, you may expect me to present some better way of doing things.
However… as unfortunate as it is, I can only circle back to the poem at the very beginning of this article, and say… I have no clue. I am unable to present the good alternative, mainly because I think we have not yet discovered it7. We hear about new privacy nightmares in large networks almost every day, and everyone is looking to us, the implementers of alternative social networking applications, in the hopes that we come up with something new and fancy that everyone is going to use. But as of right now, we are unable to deliver.
The (maybe sad?) reality is that some of the problems we are trying to solve are not technical problems at all; we could probably figure something out if we get confronted with technical challenges. Some of the issues that block mainstream adoption of alternative social media are social issues, and these cannot be solved by designing beautiful user interfaces, building great protocols, using strong encryption, and distributing the data as efficiently as possible.
If we want new approaches to social networking to be successful, we have to find a way of changing people’s expectations and behaviors. The future will not look and feel like Facebook or Twitter; it will be something else. Some things will be different, some things will be new, some things will be missing. And maybe, the best way to approach building alternative social networks is to research and solve those issues first, and then we can build technical solutions around that.
Footnotes
-
Yes, I call large platforms like Twitter and Facebook “legacy,” because to me, that’s what they are: currently still very popular, but not where we should be, and hopefully deemed to be replaced. ↩
-
These examples are an oversimplification of the reality, but I hope to get the core concepts across for non-technical people. ↩
-
This is obviously not entirely true: if your peer does not have access to the internet, then you will have a hard time sending data to them. Also, bandwidth limitations might make sharing larger contents hard. But in general, P2P systems are somewhat hard to influence once the connection is established. ↩
-
One of the most significant hurdles in having P2P networks running on mobile network connections is the fact that most carriers put mobile devices behind carrier-grade NAT, which makes it nearly impossible to accept incoming connections that one would need for incoming P2P connections. There are workarounds for this issue, but even if we consider those as suitable, having a service on smartphones that continually waits for incoming connections would ruin the device’s battery life. ↩
-
I am assuming that the underlying crypto does not break. However, that is an assumption we generally have to make when talking about these topics, as breaking crypto is a risk that will destroy all our ideas regardless of how they look. ↩
-
There are several possible solutions, like implementing a recovery key mechanism like the one sometimes used for two-factor authentication. However, I doubt that will save a lot of people because chances are high this information will get lost as well. ↩
-
No, a blockchain is not part of the answer. ↩